Deduplication. Sounds like a made up word, doesn’t it?
People are always looking for ways to improve storage usage and one of the most recent developments takes it to a new level. Since the concept is fairly new, it has several names. Deduplication, capacity optimization, single instance storage, content-addressable storage and delta encoding are the main ones. Based on Wikipedia, it appears that capacity optimization is the most common.
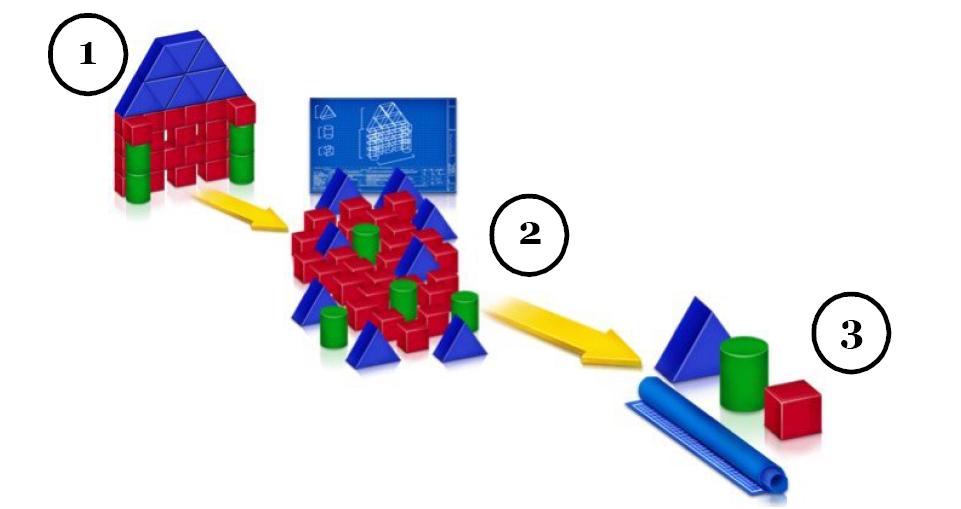
The concept of how it works is fairly simple. Instead of storing the same things over and over again, the common patterns are found and all the duplicates are removed. The key is to remember how the pieces fit together. The analogy is that you have a block structure with different shapes. With these shapes you can build many different things. However, you only have so many block shapes. Instead of storing all the pieces, it is far more efficient to only store different blocks and keep the directions of how to put the blocks together. This analogy comes straight from a very clear paper entitled “Capacity optimization: A core storage technology” by Brad O’Neill. Please read it if you would like a deeper explanation.
Why would you want this?
Well, the first noticeable benefit is greatly reduced storage requirements. For example, if you had a file server based on deduplication/capacity optimization, it would be possible to shrink the data from 100% usage to 5% usage. This is a very rough estimate based solely on the paper mentioned above.
The second benefit would come from differencing. In the world of backups, it is common for the content to remain roughly the sake. If the backup system uses deduplication, it becomes much easier to manage the differences and shrink the size of the backups. This translates into the ability to do more backups with much less space.
The third benefit would come from a VDI based solution. Given that users are essentially running the same image, deduplication would greatly reduce the overhead of the users having the same files. This would not only improve the storage usage, but potentially it would speed up the loading of the VM images. The reason why is that the common blocks are more likely to be cached versus being spread across the disk with different copies. All this would be transparent to the user.
There is another branch of this idea that targets improving network bandwidth utilization. Just like the storage, the network data is pruned so that only common objects are used along with the directions of how to assemble them. Even with our faster networks, this is still a good idea.
Just recently I’ve come to the conclusion that there is another angle for this. Most likely someone has already thought of it and implemented it as well. Feel free to let me know. Instead of being based on chunks of data (assuming it matches with disk blocks), it might be more interesting to base it on files. That way you would essentially be keeping a dictionary of files with directions of how to build anything out of them. This would allow for supporting multiple operating systems of Windows and even multiple service packs and hot fixes. The core value is treating these files as blocks. The directions would list how to put those files together to put together a solution. It’s highly abstract, but this is something worth considering. In the case of VDI, it would shrink the core operating piece down to practically nothing. Given that Windows could easy contain 200MB or more worth of files, that’s a sizable savings when duplicated for hundreds or thousands of users.
Having written this down, it makes even more sense now. There must be someone already doing this.
Maybe NetApp? They seem clever from what I’ve seen so far. They certainly have been ahead of the curve.
Getting back to deduplication, there is a real file system implementation as part of Plan9 called Venti. It is a bit more research focused but it does prove that this has been working in research labs for quite some time.
Most of the past and current focus is on providing a better backup mechanism than using a tape drive. I would predict that this will shift into more mainstream usage in file servers and data bases. It’s already happening so that prediction is not much of a stretch.
The one thing that does surface from the Venti presentation is that the way we thinking about disks is about to change. Instead of being based on blocks and locations, it is going to be based on chunks of data and their hashes. This is what allows the data to be unique on the disk. The reading seemed a bit strange but now I would conclude that what you are really reading is the hashes/indexes that can be used to retrieve the actual data automatically. A file internally would just have a sequence of identifiers for the data segments.
While writing this I also realized that this technique could be treated recursively. In that way, if you had the same directions for multiple files, you could eliminate the duplicate instructions. This could also be true for directories and whole user drives. If absolutely anything is duplicated in any way, it could be rolled up into one instance. I just imaged it be a multi-step process where it starts at the bottom and works its way back to the root. By the time you are done, there should be no duplicates of anything.
This is really just an excuse for me to think about things that probably were solved many years ago. It’s fun to pretend that no one else has done this yet but I know it isn’t true. Just let me know who is doing this! 🙂
Live near Brisbane, Australia. Software developer currently focused on iOS and Android. Avid Google Local Guide

Dear Jeff,
I think this has been done already at so many levels. For example, Windows Home Server supports it as Single Instance Store:
http://en.wikipedia.org/wiki/Single_Instance_Store
Network level? What about Citrix WANScaler cache? It maps big data chunks to smaller strings so data across the wire is compressed automatically.
Disk image level? Windows Image Format supports single instance store, and Citrix Provisioning Server (Ardence) allows you to boot several servers from SAN, preventing configuration issues and local disk problems. For VDI, check Citrix Provisioning Server for Desktops.
I was referred to SIS not long after writing this blog post. I didn’t know that Microsoft had already invested so much in reducing storage space.
WIM is an interesting format and I was surprised to find it being used for Vista deployments.
Ardence doesn’t have a true SIS/deduplication feature but they do have a shared image model. It seems that the next step is to give it more SIS like abilities for non-shared images.